一、merge(合并)的语法:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
参数介绍:
left,right:要merge的dataframe或者有name的Series
how:join类型,'left', 'right', 'outer', 'inner'
on:join的key,left和right都需要有这个key
left_on:left的df或者series的key
right_on:right的df或者seires的key
left_index,right_index:使用index而不是普通的column做join
suffixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是('_x', '_y')
二、以关键列来合并两个dataframe
可以看到只有left和right的key1=y的行保留了下来,即默认合并后只保留有共同列项并且值相等行(即交集)。
本例中left和right的k1=y分别有2个,最终构成了2*2=4行
import pandas as pd
left = pd.DataFrame({'A': ['a0', 'a1', 'a2', 'a3'],
'B': ['b0', 'b1', 'b2', 'b3'],
'k1': ['x', 'x', 'y', 'y']})
right = pd.DataFrame({'C': ['c1', 'c2', 'c3', 'c4'],
'D': ['d1', 'd2', 'd3', 'd4'],
'k1': ['y', 'y', 'z', 'z']})
left

right

pd.merge(left, right, on=‘k1’)

三、理解merge时数量的对齐关系
one-to-one:一对一关系,关联的key都是唯一的
比如(学号,姓名) merge (学号,年龄)
结果条数为:1*1
one-to-many:一对多关系,左边唯一key,右边不唯一key
比如(学号,姓名) merge (学号,[语文成绩、数学成绩、英语成绩])
结果条数为:1*N
many-to-many:多对多关系,左边右边都不是唯一的
比如(学号,[语文成绩、数学成绩、英语成绩]) merge (学号,[篮球、足球、乒乓球])
结果条数为:M*N
1、one-to-one 一对一关系的merge
left = pd.DataFrame({'sno': [11, 12, 13, 14],
'name': ['name_a', 'name_b', 'name_c', 'name_d']
})
right = pd.DataFrame({'sno': [11, 12, 13, 14],
'age': ['21', '22', '23', '24']
})
left

right
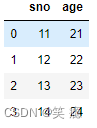
# 一对一关系,结果中有4条 pd.merge(left, right, on='sno')
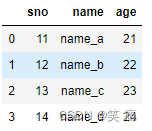
2、one-to-many 一对多关系的merge
注意:数据会被复制
left = pd.DataFrame({'sno': [11, 12, 13, 14],
'name': ['name_a', 'name_b', 'name_c', 'name_d']
})
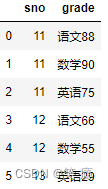
right = pd.DataFrame({'sno': [11, 11, 11, 12, 12, 13],
'grade': ['语文88', '数学90', '英语75','语文66', '数学55', '英语29']
})
left

right
# 数目以多的一边为准 pd.merge(left, right, on='sno')
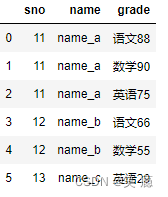
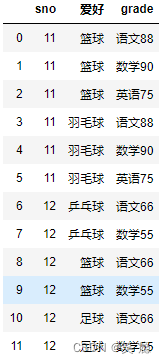
3、many-to-many 多对多关系的merge
注意:结果数量会出现乘法
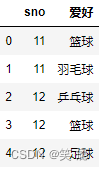
left = pd.DataFrame({'sno': [11, 11, 12, 12,12],
'爱好': ['篮球', '羽毛球', '乒乓球', '篮球', "足球"]
})
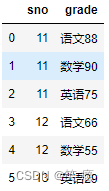
right = pd.DataFrame({'sno': [11, 11, 11, 12, 12, 13],
'grade': ['语文88', '数学90', '英语75','语文66', '数学55', '英语29']
})
left
right
pd.merge(left, right, on=‘sno’)
四、理解left join、right join、inner join、outer join的区别
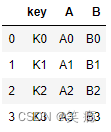
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K4', 'K5'],
'C': ['C0', 'C1', 'C4', 'C5'],
'D': ['D0', 'D1', 'D4', 'D5']})
left
right
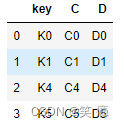
1、inner join,默认
左边和右边的key都有,才会出现在结果里
pd.merge(left, right, how='inner')

2、left join
左边的都会出现在结果里,右边的如果无法匹配则为Null
pd.merge(left, right, how='left')

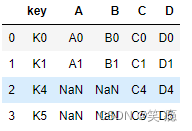
3、 right join
右边的都会出现在结果里,左边的如果无法匹配则为Null
pd.merge(left, right, how='right')
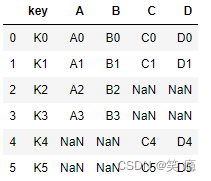
4、 outer join
左边、右边的都会出现在结果里,如果无法匹配则为Null
pd.merge(left, right, how='outer')
五、如果出现非Key的字段重名怎么办
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K4', 'K5'],
'A': ['A10', 'A11', 'A12', 'A13'],
'D': ['D0', 'D1', 'D4', 'D5']})
left

right

pd.merge(left, right, on='key')

pd.merge(left, right, on='key', suffixes=('_left', '_right'))

总结
到此这篇关于Pandas实现DataFrame合并的文章就介绍到这了,更多相关Pandas DataFrame合并内容请搜索Devmax以前的文章或继续浏览下面的相关文章希望大家以后多多支持Devmax!