在我2020年大三的一个实训的大作业中,我整了一个新冠肺炎疫情的数据采集和可视化分析系统,大致就是先找数据,然后将数据导入hive中,然后使用hive对数据进行清洗,然后将清洗后的数据使用hql导入MySql,之后就是用ssm开发后台数据接口,然后前端使用echarts和表格对数据进行可视化。具体可以查看:https://www.jb51.net/article/179889.htm。由于那时候主要要求使用hive处理数据,但那时的数据是来自于某位大佬的数据接口中获取的,最后用hive处理再导入数据库的确是大材小用。因此只是在数据的处理上不太妥,其他对数据的处理和数据的可视化做的还是不错的。
这次是有位小伙伴也想做一个疫情的数据采集和可视化系统,想借鉴我之前做的,并且让我指点。那么问题就来了:之前的数据是比较少的,直接从网上提供的免费接口就可以直接获取,而现在疫情已经过去了两年多,如果要整理出历史各省份、 城市每一天的数据,那这个数据就相对庞大,再想找现成的符合功能的接口几乎是没有,因此我做了以下的工作获取数据和处理数据:
1. 数据获取
数据的来源是用了GitHub上这个我收藏了很久的项目:https://lab.isaaclin.cn/nCoV/
数据仓库链接:https://github.com/BlankerL/DXY-COVID-19-Data/releases

这个另外部署了一个数据仓库,每天0点,程序将准时执行,数据会被推送至Release中。
我们就可以从大佬的那个数据仓库直接下载现成爬虫爬取的数据,数据直接下载csv格式的DXYArea.csv就好了,方便用于做处理。
下载后打开,会发现这个92MB的的文件里面有近100W条数据。直接读取的话肯定会有点慢了。
因此这时候我就想到可以尝试使用python的pandas分块读取数据,这个工具对数据处理很方便,对数据的读取也贼快。
2. 使用python读取csv
读取csv选择使用pandas模块,使用原生读取很对很慢
注:py脚本文件和csv文件放在同一目录下
import pandas as pd
import numpy as np
# 读取的文件
filePath = "DXYArea.csv"
# 获取数据
def read_csv_feature(filePath):
# 读取文件
f = open(filePath, encoding='utf-8')
reader = pd.read_csv(f, sep=',', iterator=True)
loop = True
chunkSize = 1000000
chunks = []
while loop:
try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
df = pd.concat(chunks, axis=0, ignore_index=True)
f.close()
return df
data = read_csv_feature(filePath)
print('数据读取成功---------------')
csv数据读取成功之后,就全部存在data里面了,而这个data是一个数据集。
可以使用numpy模块工具对数据集进行筛选、导出转换成list,方便对数据进行操作
countryName = np.array(data["countryName"]) countryEnglishName = np.array(data["countryEnglishName"]) provinceName = np.array(data["provinceName"]) province_confirmedCount = np.array(data["province_confirmedCount"]) province_curedCount = np.array(data["province_curedCount"]) province_deadCount = np.array(data["province_deadCount"]) updateTime = np.array(data["updateTime"]) cityName = np.array(data["cityName"]) city_confirmedCount = np.array(data["city_confirmedCount"]) city_curedCount = np.array(data["city_curedCount"]) city_deadCount = np.array(data["city_deadCount"])
这样就把所有需要用到的数据筛选出来了。
3.使用pyhon进行数据清洗
这里的清洗我还是使用了笨方法,很直接暴力的把数据装进对应的list中:
# 全国历史数据
historyed = list()
# 全国最新数据
totaled = list()
# province最新数据
provinceed = list()
# area最新数据
areaed = list()
for i in range(len(data)):
if(countryName[i] == "中国"):
updatetimeList = str(updateTime[i]).split(' ')
updatetime = updatetimeList[0]
# 处理historyed
historyed_temp = list()
if(provinceName[i] == "中国"):
# 处理totaled
if(len(totaled) == 0):
totaled.append(str(updateTime[i]))
totaled.append(int(province_confirmedCount[i]))
totaled.append(int(province_curedCount[i]))
totaled.append(int(province_deadCount[i]))
if((len(historyed) > 0) and (str(updatetime) != historyed[len(historyed) - 1][0])):
historyed_temp.append(str(updatetime))
historyed_temp.append(int(province_confirmedCount[i]))
historyed_temp.append(int(province_curedCount[i]))
historyed_temp.append(int(province_deadCount[i]))
if(len(historyed) == 0):
historyed_temp.append(str(updatetime))
historyed_temp.append(int(province_confirmedCount[i]))
historyed_temp.append(int(province_curedCount[i]))
historyed_temp.append(int(province_deadCount[i]))
if(len(historyed_temp) > 0):
historyed.append(historyed_temp)
# 处理areaed
areaed_temp = list()
if(provinceName[i] != "中国"):
if(provinceName[i] != "内蒙古自治区" and provinceName[i] != "黑龙江省"):
provinceName[i] = provinceName[i][0:2]
else:
provinceName[i] = provinceName[i][0:3]
flag = 1
for item in areaed:
if(item[1] == str(cityName[i])):
flag = 0
if(flag == 1):
areaed_temp.append(str(provinceName[i]))
areaed_temp.append(str(cityName[i]))
areaed_temp.append(int(0 if np.isnan(city_confirmedCount[i]) else city_confirmedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_curedCount[i]) else city_curedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_deadCount[i]) else city_deadCount[i]))
areaed.append(areaed_temp)
flag = 1
for item in areaed_tmp:
if(item[0] == str(provinceName[i])):
flag = 0
if(flag == 1):
areaed_temp.append(str(provinceName[i]))
areaed_temp.append(str(cityName[i]))
areaed_temp.append(int(0 if np.isnan(city_confirmedCount[i]) else city_confirmedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_curedCount[i]) else city_curedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_deadCount[i]) else city_deadCount[i]))
areaed_tmp.append(areaed_temp)
# 处理provinceed(需要根据areaed获取)
province_temp = list()
for temp in areaed_tmp:
if(len(provinceed) == 0 and len(province_temp) == 0):
province_temp.append(temp[0])
province_temp.append(temp[2])
province_temp.append(temp[3])
province_temp.append(temp[4])
else:
if(temp[0] == province_temp[0]):
province_temp[1] = province_temp[1] temp[2]
province_temp[1] = province_temp[2] temp[3]
province_temp[1] = province_temp[3] temp[4]
else:
provinceed.append(province_temp)
province_temp = list()
province_temp.append(temp[0])
province_temp.append(temp[2])
province_temp.append(temp[3])
province_temp.append(temp[4])
provinceed.append(province_temp)
print('数据清洗成功---------------')
这里没有什么说的,完全是体力活,将上面筛选出来的数据进行清洗,需要注意的是要仔细的观察读取出来的数据的数据格式,有些数据格式不是很标准,需要手动处理。
4. 将清洗的数据自动导入MySql
将数据导入Mysql这里还是使用python,使用了python的pymysql模块
import pymysql
"""
将数据导入数据库
"""
# 打开数据库连接
db=pymysql.connect(host="localhost",user="root",password="123456",database="yq")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
#创建yq数据库
cursor.execute('CREATE DATABASE IF NOT EXISTS yq DEFAULT CHARSET utf8 COLLATE utf8_general_ci;')
print('创建yq数据库成功')
#创建相关表表
cursor.execute('drop table if exists areaed')
sql="""
CREATE TABLE IF NOT EXISTS `areaed` (
`provinceName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`cityName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`confirmedCount` int(11) NULL DEFAULT NULL,
`deadCount` int(11) NULL DEFAULT NULL,
`curedCount` int(11) NULL DEFAULT NULL,
`currentCount` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
"""
cursor.execute(sql)
cursor.execute('drop table if exists provinceed')
sql="""
CREATE TABLE `provinceed` (
`provinceName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`confirmedNum` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`deathsNum` int(11) NULL DEFAULT NULL,
`curesNum` int(11) NULL DEFAULT NULL,
`currentNum` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
"""
cursor.execute(sql)
cursor.execute('drop table if exists totaled')
sql="""
CREATE TABLE `totaled` (
`date` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`diagnosed` int(11) NULL DEFAULT NULL,
`death` int(11) NULL DEFAULT NULL,
`cured` int(11) NULL DEFAULT NULL,
`current` int(11) NULL DEFAULT NULL
) ENGINE = MyISAM CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
"""
cursor.execute(sql)
cursor.execute('drop table if exists historyed')
sql="""
CREATE TABLE `historyed` (
`date` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`confirmedNum` int(11) NULL DEFAULT NULL,
`deathsNum` int(11) NULL DEFAULT NULL,
`curesNum` int(11) NULL DEFAULT NULL,
`currentNum` int(11) NULL DEFAULT NULL
) ENGINE = MyISAM CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
"""
cursor.execute(sql)
print('创建相关表成功')
# 导入historyed
for item in historyed:
sql='INSERT INTO historyed VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(item[0]),item[1],item[3],item[2],item[1]-item[2]-item[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入historyed成功-------------")
# 导入areaed
for item in areaed:
sql='INSERT INTO areaed VALUES(%s,"%s","%s","%s","%s","%s")'
try:
cursor.execute(sql,(item[0],item[1],item[2],item[4],item[3],item[2]-item[3]-item[4]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入areaed成功-------------")
# 导入provinceed
for item in provinceed:
sql='INSERT INTO provinceed VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(item[0]),item[1],item[3],item[2],item[1]-item[2]-item[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入provinceed成功-------------")
# 导入totaled
sql='INSERT INTO totaled VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(totaled[0]),totaled[1],totaled[3],totaled[2],totaled[1]-totaled[2]-totaled[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
print("导入totaled成功-------------")
cursor.close()#先关闭游标
db.close()#再关闭数据库连接
这里为了脚本的使用方便,首先进行了建库、然后建表、最后将清洗的数据导入MySql
完整代码
import pandas as pd
import numpy as np
import pymysql
"""
@ProjectName: cleanData
@FileName: cleanData.py
@Author: tao
@Date: 2022/05/03
"""
# 读取的文件
filePath = "DXYArea.csv"
# 全国历史数据
historyed = list()
# 全国最新数据
totaled = list()
# province最新数据
provinceed = list()
# area最新数据
areaed = list()
# 获取数据
def read_csv_feature(filePath):
# 读取文件
f = open(filePath, encoding='utf-8')
reader = pd.read_csv(f, sep=',', iterator=True)
loop = True
chunkSize = 1000000
chunks = []
while loop:
try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
df = pd.concat(chunks, axis=0, ignore_index=True)
f.close()
return df
data = read_csv_feature(filePath)
print('数据读取成功---------------')
areaed_tmp = list()
countryName = np.array(data["countryName"])
countryEnglishName = np.array(data["countryEnglishName"])
provinceName = np.array(data["provinceName"])
province_confirmedCount = np.array(data["province_confirmedCount"])
province_curedCount = np.array(data["province_curedCount"])
province_deadCount = np.array(data["province_deadCount"])
updateTime = np.array(data["updateTime"])
cityName = np.array(data["cityName"])
city_confirmedCount = np.array(data["city_confirmedCount"])
city_curedCount = np.array(data["city_curedCount"])
city_deadCount = np.array(data["city_deadCount"])
for i in range(len(data)):
if(countryName[i] == "中国"):
updatetimeList = str(updateTime[i]).split(' ')
updatetime = updatetimeList[0]
# 处理historyed
historyed_temp = list()
if(provinceName[i] == "中国"):
# 处理totaled
if(len(totaled) == 0):
totaled.append(str(updateTime[i]))
totaled.append(int(province_confirmedCount[i]))
totaled.append(int(province_curedCount[i]))
totaled.append(int(province_deadCount[i]))
if((len(historyed) > 0) and (str(updatetime) != historyed[len(historyed) - 1][0])):
historyed_temp.append(str(updatetime))
historyed_temp.append(int(province_confirmedCount[i]))
historyed_temp.append(int(province_curedCount[i]))
historyed_temp.append(int(province_deadCount[i]))
if(len(historyed) == 0):
historyed_temp.append(str(updatetime))
historyed_temp.append(int(province_confirmedCount[i]))
historyed_temp.append(int(province_curedCount[i]))
historyed_temp.append(int(province_deadCount[i]))
if(len(historyed_temp) > 0):
historyed.append(historyed_temp)
# 处理areaed
areaed_temp = list()
if(provinceName[i] != "中国"):
if(provinceName[i] != "内蒙古自治区" and provinceName[i] != "黑龙江省"):
provinceName[i] = provinceName[i][0:2]
else:
provinceName[i] = provinceName[i][0:3]
flag = 1
for item in areaed:
if(item[1] == str(cityName[i])):
flag = 0
if(flag == 1):
areaed_temp.append(str(provinceName[i]))
areaed_temp.append(str(cityName[i]))
areaed_temp.append(int(0 if np.isnan(city_confirmedCount[i]) else city_confirmedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_curedCount[i]) else city_curedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_deadCount[i]) else city_deadCount[i]))
areaed.append(areaed_temp)
flag = 1
for item in areaed_tmp:
if(item[0] == str(provinceName[i])):
flag = 0
if(flag == 1):
areaed_temp.append(str(provinceName[i]))
areaed_temp.append(str(cityName[i]))
areaed_temp.append(int(0 if np.isnan(city_confirmedCount[i]) else city_confirmedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_curedCount[i]) else city_curedCount[i]))
areaed_temp.append(int(0 if np.isnan(city_deadCount[i]) else city_deadCount[i]))
areaed_tmp.append(areaed_temp)
# 处理provinceed(需要根据areaed获取)
province_temp = list()
for temp in areaed_tmp:
if(len(provinceed) == 0 and len(province_temp) == 0):
province_temp.append(temp[0])
province_temp.append(temp[2])
province_temp.append(temp[3])
province_temp.append(temp[4])
else:
if(temp[0] == province_temp[0]):
province_temp[1] = province_temp[1] temp[2]
province_temp[1] = province_temp[2] temp[3]
province_temp[1] = province_temp[3] temp[4]
else:
provinceed.append(province_temp)
province_temp = list()
province_temp.append(temp[0])
province_temp.append(temp[2])
province_temp.append(temp[3])
province_temp.append(temp[4])
provinceed.append(province_temp)
print('数据清洗成功---------------')
# print(historyed)
# print(areaed)
print(totaled)
# print(provinceed)
"""
print(len(provinceed))
for item in provinceed:
print(item[1]-item[2]-item[3])
"""
"""
将数据导入数据库
"""
# 打开数据库连接
db=pymysql.connect(host="localhost",user="root",password="123456",database="yq")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
#创建yq数据库
cursor.execute('CREATE DATABASE IF NOT EXISTS yq DEFAULT CHARSET utf8 COLLATE utf8_general_ci;')
print('创建yq数据库成功')
#创建相关表表
cursor.execute('drop table if exists areaed')
sql="""
CREATE TABLE IF NOT EXISTS `areaed` (
`provinceName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`cityName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`confirmedCount` int(11) NULL DEFAULT NULL,
`deadCount` int(11) NULL DEFAULT NULL,
`curedCount` int(11) NULL DEFAULT NULL,
`currentCount` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
"""
cursor.execute(sql)
cursor.execute('drop table if exists provinceed')
sql="""
CREATE TABLE `provinceed` (
`provinceName` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`confirmedNum` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`deathsNum` int(11) NULL DEFAULT NULL,
`curesNum` int(11) NULL DEFAULT NULL,
`currentNum` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
"""
cursor.execute(sql)
cursor.execute('drop table if exists totaled')
sql="""
CREATE TABLE `totaled` (
`date` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`diagnosed` int(11) NULL DEFAULT NULL,
`death` int(11) NULL DEFAULT NULL,
`cured` int(11) NULL DEFAULT NULL,
`current` int(11) NULL DEFAULT NULL
) ENGINE = MyISAM CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
"""
cursor.execute(sql)
cursor.execute('drop table if exists historyed')
sql="""
CREATE TABLE `historyed` (
`date` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`confirmedNum` int(11) NULL DEFAULT NULL,
`deathsNum` int(11) NULL DEFAULT NULL,
`curesNum` int(11) NULL DEFAULT NULL,
`currentNum` int(11) NULL DEFAULT NULL
) ENGINE = MyISAM CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
"""
cursor.execute(sql)
print('创建相关表成功')
# 导入historyed
for item in historyed:
sql='INSERT INTO historyed VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(item[0]),item[1],item[3],item[2],item[1]-item[2]-item[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入historyed成功-------------")
# 导入areaed
for item in areaed:
sql='INSERT INTO areaed VALUES(%s,"%s","%s","%s","%s","%s")'
try:
cursor.execute(sql,(item[0],item[1],item[2],item[4],item[3],item[2]-item[3]-item[4]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入areaed成功-------------")
# 导入provinceed
for item in provinceed:
sql='INSERT INTO provinceed VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(item[0]),item[1],item[3],item[2],item[1]-item[2]-item[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
break
print("导入provinceed成功-------------")
# 导入totaled
sql='INSERT INTO totaled VALUES(%s,"%s","%s","%s","%s")'
try:
cursor.execute(sql,(str(totaled[0]),totaled[1],totaled[3],totaled[2],totaled[1]-totaled[2]-totaled[3]))
db.commit()
except Exception as ex:
print("error:")
print("出现如下异常%s"%ex)
db.rollback()
print("导入totaled成功-------------")
cursor.close()#先关闭游标
db.close()#再关闭数据库连接
脚本运行效果

数据库可以看到以下表和数据
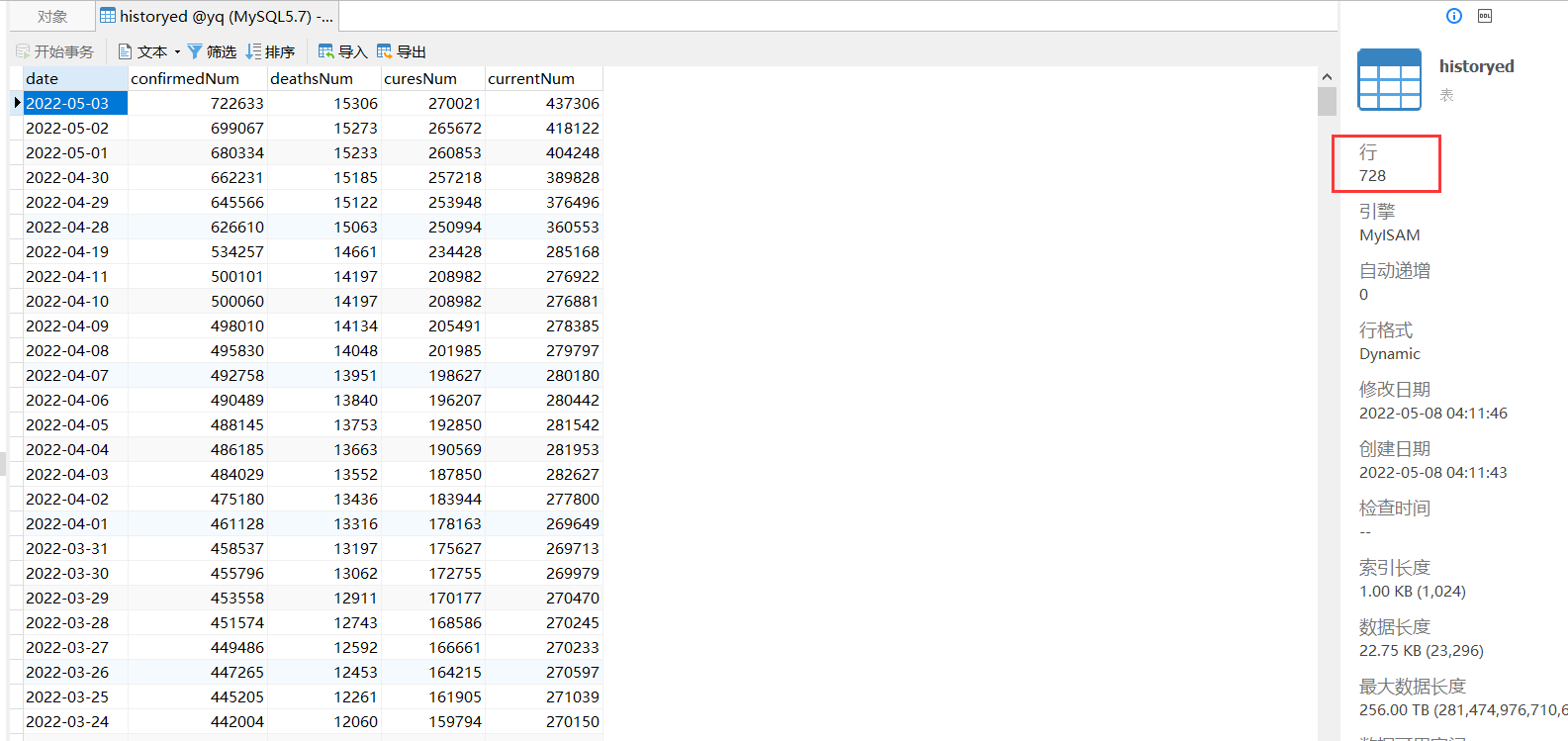
最后我们的数据就已经有了,此时的数据处理的格式还是参照我之前整的新冠肺炎疫情的数据采集和可视化分析系统对接的,集体后台和可视化的实现可以参考:https://qkongtao.cn/?p=514
到此这篇关于python清洗疫情历史数据的文章就介绍到这了,更多相关python疫情历史数据内容请搜索Devmax以前的文章或继续浏览下面的相关文章希望大家以后多多支持Devmax!