检查网页无效链接
前言
自动化技术可以帮助我们做自动化测试,同样也可以帮助我们完成别的事情,比如今天我们要做的检查网站404无效链接。
原理
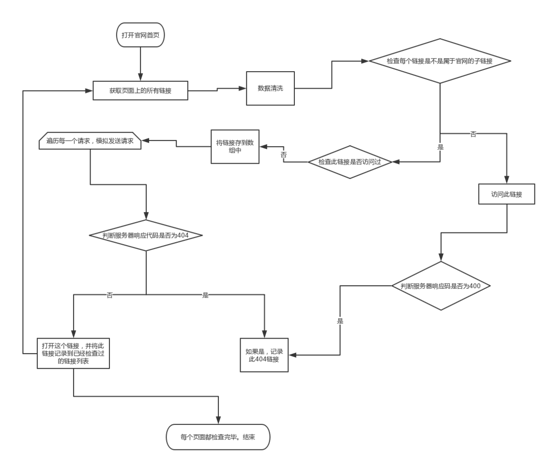
实现这样的功能,大致分为以下步骤: 1.打开官网首页,获取页面上所有的链接。 2.添加规则对这些链接过滤,把外链去掉。 3.遍历访问这些链接,打开打开其中的每一个链接,检查是否为404,如果是距离下来。 4.重复执行1,2,3。直到把整个网站所有的链接都遍历完。
准备
CukeTest 一款可以专业的编辑自动化脚本的工具。cuketest.com/
puppeteer 一个非常流行自动化库。https://github.com/GoogleChrome/puppeteer
实现
CukeTest中新建一个项目。
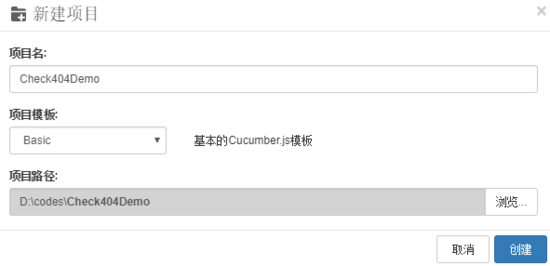
删掉features目录。新建一个demo.js文件。
安装puppeteer
npm install puppeteer --save
主要方法讲解
pupputeer内置监听事件,可以很快拿到每个请求的响应结果。
puppeteer可以创建Chromium实例。创建方式如下:
let puppeteer = require('puppeteer');
browser = await puppeteer.launch({ headless: true });
page = await browser.newPage();
await browser.close();
puppeteer 提供事件监听,可以监听到每个页面的响应状态,为每个请求添加响应事件,如果响应状态码为404,记录到文件中。
page.on('response',(res)=>{
// console.log("res.url", res.url(), res.status())
let url = res.url();
if(res.status()==404){
linktoFile(url, brokenlinkFile);
}else{
if(isvaildUrl(url)){
linktoFile(url,validUrlFilePath);
}
}
})
puppeteer抓取页面上所有的链接
await page.goto(url);
//获取所有的link
const hrefs = await page.evaluate(
() => Array.from(document.body.querySelectorAll('a[href]'), ({ href }) => href)
);
将链接记录到文件或者从文件读取链接的方法
let filetoLinks = function (filepath) {
if (!fs.existsSync(filepath)) {
fs.writeFileSync(filepath);
}
let data = fs.readFileSync(filepath, 'utf-8')
let links = data.trim().split('\n');
return links;
}
let linktoFile = function (link, filepath) {
let foundLinks = filetoLinks(filepath);
if (!foundLinks.includes(link)) {
fs.appendFileSync(filepath, link '\n');
}
}
最终代码
let puppeteer = require('puppeteer');
const fs = require('fs');
const path = require('path');
const host = 'http://www.xxxx.cn/'; // 被测网站
const visitedFile = 'visitedUrl.txt'; //浏览过的页面
const visitedFilePath = path.join(__dirname, visitedFile);
const brokenlinkFile = 'brokenLink.txt'; //404链接
const brokenlinkFilePath = path.join(__dirname, brokenlinkFile);
const validUrlFile = 'validUrlFile.txt'; //可用的链接
const validUrlFilePath = path.join(__dirname,validUrlFile);
let browser;
let page;
function isvaildUrl(url){
return url.startsWith(host) && !url.includes('/#');
}
async function run() {
browser = await puppeteer.launch({ headless: true });
page = await browser.newPage();
page.on('response',(res)=>{
// console.log("res.url", res.url(), res.status())
let url = res.url();
let currenturl = page.url()
if(res.status()==404){
linktoFile(currenturl "==" url, brokenlinkFilePath);
}else{
if(isvaildUrl(url)){
linktoFile(url,validUrlFilePath);
}
}
})
await visitPage(browser,page, host);
await browser.close();
}
async function visitPage(browser,page, url) {
// if (!isvaildUrl(url)) return;
await page.goto(url);
//获取所有的link
const hrefs = await page.evaluate(
() => Array.from(document.body.querySelectorAll('a[href]'), ({ href }) => href)
);
for (const href of hrefs) {
//数据清洗
if (isvaildUrl(href) && href !== host) {
//符合条件的link
// linktoFile(href, visitedFilePath);
let res = await page.goto(href);
if (res && res.status() == 404) {
linktoFile(href, brokenlinkFilePath);
} else {
let visitedlinks = filetoLinks(visitedFilePath);
if(!visitedlinks.includes(href)){
linktoFile(href, visitedFilePath);
await visitPage(browser,page,href);
}
}
let links = filetoLinks(visitedFilePath);
if (!links.includes(href)) {
await visitPage(browser,page, href);
}
}
}
}
let filetoLinks = function (filepath) {
if (!fs.existsSync(filepath)) {
fs.writeFileSync(filepath);
}
let data = fs.readFileSync(filepath, 'utf-8')
let links = data.trim().split('\n');
return links;
}
let linktoFile = function (link, filepath) {
let foundLinks = filetoLinks(filepath);
if (!foundLinks.includes(link)) {
fs.appendFileSync(filepath, link '\n');
}
}
run();
运行
点击 【运行】按钮即可运行。 同样,在CukeTest中也支持命令行执行,执行命令为
cuke --runjs demo.js
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Devmax。