前言
……最近在学习yolo1、yolo2和yolo3,写这篇博客主要是为了让自己对yolo2的结构有更加深刻的理解,同时要理解清楚先验框的含义。
尽量配合代码观看会更容易理解。
下载链接:https://pan.baidu.com/s/1NAqme8dD2Zoeo1Yd1xQVFw
提取码:oq05
实现思路
1、yolo2的预测思路(网络构建思路)
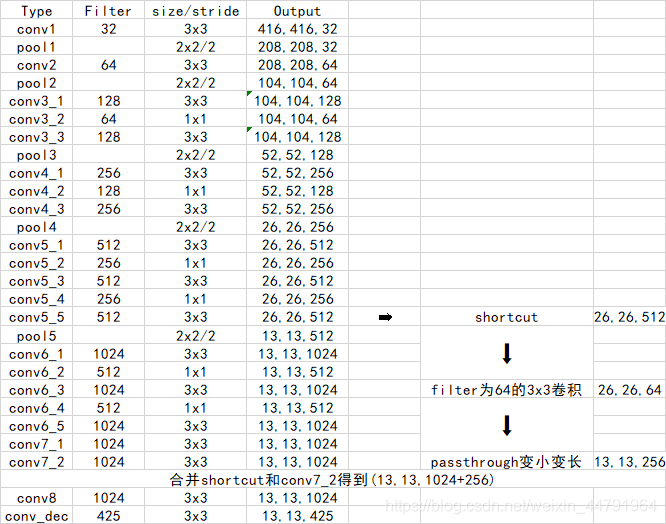
YOLOv2使用了一个新的分类网络DarkNet19作为特征提取部分,DarkNet19包含19个卷积层、5个最大值池化层。网络使用了较多的3 x 3卷积核,在每一次池化操作后把通道数翻倍。借鉴了network in network的思想,把1 x 1的卷积核置于3 x 3的卷积核之间,用来压缩特征。使用batch normalization稳定模型训练,加速收敛,正则化模型。
与此同时,其保留了一个shortcut用于存储之前的特征。
最后输出的conv_dec的shape为(13,13,425),其中13x13是把整个图分为13x13的网格用于预测,425可以分解为(85x5),在85中,其可以分为80和5两部分,由于yolo2常用的是coco数据集,其中具有80个类,剩余的5指的是x、y、w、h和其置信度。x5的5中,意味着预测结果包含5个框,分别对应5个先验框。
其实际情况就是,输入N张416x416的图片,在经过多层的运算后,会输出一个shape为(N,13,13,425)的数据,对应每个图分为13x13的网格后5个先验框的位置。
def conv2d(self,x,filters_num,filters_size,pad_size=0,stride=1,batch_normalize=True,activation=leaky_relu,use_bias=False,name='conv2d'):
# 是否进行pad
if pad_size > 0:
x = tf.pad(x,[[0,0],[pad_size,pad_size],[pad_size,pad_size],[0,0]])
# pad后进行卷积
out = tf.layers.conv2d(x,filters=filters_num,kernel_size=filters_size,strides=stride,padding='VALID',activation=None,use_bias=use_bias,name=name)
# BN应该在卷积层conv和激活函数activation之间,
# 后面有BN层的conv就不用偏置bias,并激活函数activation在后
# 如果需要标准化则进行标准化
if batch_normalize:
out = tf.layers.batch_normalization(out,axis=-1,momentum=0.9,training=False,name=name '_bn')
if activation:
out = activation(out)
return out
def maxpool(self,x, size=2, stride=2, name='maxpool'):
return tf.layers.max_pooling2d(x, pool_size=size, strides=stride,name=name)
def passthrough(self,x, stride):
# 变小变长
return tf.space_to_depth(x, block_size=stride)
def darknet(self):
x = tf.placeholder(dtype=tf.float32,shape=[None,416,416,3])
# 416,416,3 -> 416,416,32
net = self.conv2d(x, filters_num=32, filters_size=3, pad_size=1,
name='conv1')
# 416,416,32 -> 208,208,32
net = self.maxpool(net, size=2, stride=2, name='pool1')
# 208,208,32 -> 208,208,64
net = self.conv2d(net, 64, 3, 1, name='conv2')
# 208,208,64 -> 104,104,64
net = self.maxpool(net, 2, 2, name='pool2')
# 104,104,64 -> 104,104,128
net = self.conv2d(net, 128, 3, 1, name='conv3_1')
net = self.conv2d(net, 64, 1, 0, name='conv3_2')
net = self.conv2d(net, 128, 3, 1, name='conv3_3')
# 104,104,128 -> 52,52,128
net = self.maxpool(net, 2, 2, name='pool3')
net = self.conv2d(net, 256, 3, 1, name='conv4_1')
net = self.conv2d(net, 128, 1, 0, name='conv4_2')
net = self.conv2d(net, 256, 3, 1, name='conv4_3')
# 52,52,128 -> 26,26,256
net = self.maxpool(net, 2, 2, name='pool4')
# 26,26,256-> 26,26,512
net = self.conv2d(net, 512, 3, 1, name='conv5_1')
net = self.conv2d(net, 256, 1, 0, name='conv5_2')
net = self.conv2d(net, 512, 3, 1, name='conv5_3')
net = self.conv2d(net, 256, 1, 0, name='conv5_4')
net = self.conv2d(net, 512, 3, 1, name='conv5_5')
# 这一层特征图,要进行后面passthrough,保留一层特征层
shortcut = net
# 26,26,512-> 13,13,512
net = self.maxpool(net, 2, 2, name='pool5') #
# 13,13,512-> 13,13,1024
net = self.conv2d(net, 1024, 3, 1, name='conv6_1')
net = self.conv2d(net, 512, 1, 0, name='conv6_2')
net = self.conv2d(net, 1024, 3, 1, name='conv6_3')
net = self.conv2d(net, 512, 1, 0, name='conv6_4')
net = self.conv2d(net, 1024, 3, 1, name='conv6_5')
# 下面这部分主要是training for detection
net = self.conv2d(net, 1024, 3, 1, name='conv7_1')
# 13,13,1024-> 13,13,1024
net = self.conv2d(net, 1024, 3, 1, name='conv7_2')
# shortcut增加了一个中间卷积层,先采用64个1*1卷积核进行卷积,然后再进行passthrough处理
# 得到了26*26*512 -> 26*26*64 -> 13*13*256的特征图
shortcut = self.conv2d(shortcut, 64, 1, 0, name='conv_shortcut')
shortcut = self.passthrough(shortcut, 2)
# 连接之后,变成13*13*(1024 256)
net = tf.concat([shortcut, net],axis=-1)
# channel整合到一起,concatenated with the original features,passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上,
net = self.conv2d(net, 1024, 3, 1, name='conv8')
# detection layer: 最后用一个1*1卷积去调整channel,该层没有BN层和激活函数,变成: S*S*(B*(5 C)),在这里为:13*13*425
output = self.conv2d(net, filters_num=self.f_num, filters_size=1, batch_normalize=False, activation=None,
use_bias=True, name='conv_dec')
return output,x
2、先验框的生成
对于yolo1来讲,其最后输出的结果的shape为(7,7,30),对应着两个框及其种类,尽管网络可以不断的训练最后实现框的位置的调整,但是如果我们能够给出一些框的尺寸备用,效果理论上会更好(实际上也是),这就是先验框的来历。
但是yolo2的框并不是随便就得到的,它是通过计算得到的。
在寻常的kmean算法中,使用的是欧氏距离来完成聚类,但是先验框显然不可以这样,因为大框的欧氏距离更大,yolo2使用的是处理后的IOU作为欧氏距离。

最后得到五个聚类中心便是先验框的宽高。
import numpy as np
import xml.etree.ElementTree as ET
import glob
import random
def cas_iou(box,cluster):
x = np.minimum(cluster[:,0],box[0])
y = np.minimum(cluster[:,1],box[1])
intersection = x * y
area1 = box[0] * box[1]
area2 = cluster[:,0] * cluster[:,1]
iou = intersection / (area1 area2 -intersection)
return iou
def avg_iou(box,cluster):
return np.mean([np.max(cas_iou(box[i],cluster)) for i in range(box.shape[0])])
def kmeans(box,k):
# 取出一共有多少框
row = box.shape[0]
# 每个框各个点的位置
distance = np.empty((row,k))
# 最后的聚类位置
last_clu = np.zeros((row,))
np.random.seed()
# 随机选5个当聚类中心
cluster = box[np.random.choice(row,k,replace = False)]
# cluster = random.sample(row, k)
while True:
# 计算每一行距离五个点的iou情况。
for i in range(row):
distance[i] = 1 - cas_iou(box[i],cluster)
# 取出最小点
near = np.argmin(distance,axis=1)
if (last_clu == near).all():
break
# 求每一个类的中位点
for j in range(k):
cluster[j] = np.median(
box[near == j],axis=0)
last_clu = near
return cluster
def load_data(path):
data = []
# 对于每一个xml都寻找box
for xml_file in glob.glob('{}/*xml'.format(path)):
tree = ET.parse(xml_file)
height = int(tree.findtext('./size/height'))
width = int(tree.findtext('./size/width'))
# 对于每一个目标都获得它的宽高
for obj in tree.iter('object'):
xmin = int(float(obj.findtext('bndbox/xmin'))) / width
ymin = int(float(obj.findtext('bndbox/ymin'))) / height
xmax = int(float(obj.findtext('bndbox/xmax'))) / width
ymax = int(float(obj.findtext('bndbox/ymax'))) / height
xmin = np.float64(xmin)
ymin = np.float64(ymin)
xmax = np.float64(xmax)
ymax = np.float64(ymax)
# 得到宽高
data.append([xmax-xmin,ymax-ymin])
return np.array(data)
if __name__ == '__main__':
anchors_num = 5
# 载入数据集,可以使用VOC的xml
path = '../SSD-Tensorflow-master/VOC2012/Annotations'
# 载入所有的xml
# 存储格式为转化为比例后的width,height
data = load_data(path)
# 使用k聚类算法
out = kmeans(data,anchors_num)
print('acc:{:.2f}%'.format(avg_iou(data,out) * 100))
print(out)
print('box',out[:,0] * 13,out[:,1] * 13)
ratios = np.around(out[:,0]/out[:,1],decimals=2).tolist()
print('ratios:',sorted(ratios))
得到结果为:
acc:61.32% [[0.044 0.07733333] [0.106 0.17866667] [0.408 0.616 ] [0.816 0.83 ] [0.2 0.38933333]] box [ 0.572 1.378 5.304 10.608 2.6 ] [ 1.00533333 2.32266667 8.008 10.79 5.06133333] ratios: [0.51, 0.57, 0.59, 0.66, 0.98]
3、利用先验框对网络的输出进行解码
yolo2的解码过程与SSD类似,但是并不太一样,相比之下yolo2的解码过程更容易理解,因为其仅有单层的特征层。
1、将网络的输出reshape成[-1, 13 * 13, 5, 80 5],代表169个中心点每个中心点的5个先验框的情况。
2、将80 5的5中的xywh分离出来,0、1是xy相对中心点的偏移量;2、3是宽和高的情况;4是置信度。
3、建立13x13的网格,代表图片进行13x13处理后网格的中心点。
4、利用计算公式计算实际的bbox的位置 。
解码部分代码如下:
def decode(self,net):
self.anchor_size = tf.constant(self.anchor_size,tf.float32)
# net的shape为[batch,169,5,85]
net = tf.reshape(net, [-1, 13 * 13, self.num_anchors, self.num_class 5])
# 85 里面 0、1为xy的偏移量,2、3是wh的偏移量,4是置信度,5->84是每个种类的概率
# 偏移量、置信度、类别
# 中心坐标相对于该cell坐上角的偏移量,sigmoid函数归一化到(0,1)
# [batch,169,5,2]
xy_offset = tf.nn.sigmoid(net[:, :, :, 0:2])
wh_offset = tf.exp(net[:, :, :, 2:4])
obj_probs = tf.nn.sigmoid(net[:, :, :, 4])
class_probs = tf.nn.softmax(net[:, :, :, 5:])
# 在feature map对应坐标生成anchors,13,13
height_index = tf.range(self.feature_map_size[0], dtype=tf.float32)
width_index = tf.range(self.feature_map_size[1], dtype=tf.float32)
x_cell, y_cell = tf.meshgrid(height_index, width_index)
x_cell = tf.reshape(x_cell, [1, -1, 1]) # 和上面[H*W,num_anchors,num_class 5]对应
y_cell = tf.reshape(y_cell, [1, -1, 1])
# x_cell和y_cell是网格分割中心
# xy_offset是相对中心的偏移情况
bbox_x = (x_cell xy_offset[:, :, :, 0]) / 13
bbox_y = (y_cell xy_offset[:, :, :, 1]) / 13
bbox_w = (self.anchor_size[:, 0] * wh_offset[:, :, :, 0]) / 13
bbox_h = (self.anchor_size[:, 1] * wh_offset[:, :, :, 1]) / 13
bboxes = tf.stack([bbox_x - bbox_w / 2, bbox_y - bbox_h / 2, bbox_x bbox_w / 2, bbox_y bbox_h / 2],
axis=3)
return bboxes, obj_probs, class_probs
4、进行得分排序与非极大抑制筛选
这一部分基本上是所有目标检测通用的部分。
1、将所有box还原成图片中真实的位置。
2、得到每个box最大的预测概率对应的种类。
3、将每个box最大的预测概率乘上置信度得到每个box的分数。
4、对分数进行筛选与排序。
5、非极大抑制,去除重复率过大的框。
实现代码如下:
def bboxes_cut(self,bbox_min_max, bboxes):
bboxes = np.copy(bboxes)
bboxes = np.transpose(bboxes)
bbox_min_max = np.transpose(bbox_min_max)
# cut the box
bboxes[0] = np.maximum(bboxes[0], bbox_min_max[0]) # xmin
bboxes[1] = np.maximum(bboxes[1], bbox_min_max[1]) # ymin
bboxes[2] = np.minimum(bboxes[2], bbox_min_max[2]) # xmax
bboxes[3] = np.minimum(bboxes[3], bbox_min_max[3]) # ymax
bboxes = np.transpose(bboxes)
return bboxes
def bboxes_sort(self,classes, scores, bboxes, top_k=400):
index = np.argsort(-scores)
classes = classes[index][:top_k]
scores = scores[index][:top_k]
bboxes = bboxes[index][:top_k]
return classes, scores, bboxes
def bboxes_iou(self,bboxes1, bboxes2):
bboxes1 = np.transpose(bboxes1)
bboxes2 = np.transpose(bboxes2)
int_ymin = np.maximum(bboxes1[0], bboxes2[0])
int_xmin = np.maximum(bboxes1[1], bboxes2[1])
int_ymax = np.minimum(bboxes1[2], bboxes2[2])
int_xmax = np.minimum(bboxes1[3], bboxes2[3])
int_h = np.maximum(int_ymax - int_ymin, 0.)
int_w = np.maximum(int_xmax - int_xmin, 0.)
# 计算IOU
int_vol = int_h * int_w # 交集面积
vol1 = (bboxes1[2] - bboxes1[0]) * (bboxes1[3] - bboxes1[1]) # bboxes1面积
vol2 = (bboxes2[2] - bboxes2[0]) * (bboxes2[3] - bboxes2[1]) # bboxes2面积
IOU = int_vol / (vol1 vol2 - int_vol) # IOU=交集/并集
return IOU
# NMS,或者用tf.image.non_max_suppression
def bboxes_nms(self,classes, scores, bboxes, nms_threshold=0.2):
keep_bboxes = np.ones(scores.shape, dtype=np.bool)
for i in range(scores.size - 1):
if keep_bboxes[i]:
overlap = self.bboxes_iou(bboxes[i], bboxes[(i 1):])
keep_overlap = np.logical_or(overlap < nms_threshold,
classes[(i 1):] != classes[i]) # IOU没有超过0.5或者是不同的类则保存下来
keep_bboxes[(i 1):] = np.logical_and(keep_bboxes[(i 1):], keep_overlap)
idxes = np.where(keep_bboxes)
return classes[idxes], scores[idxes], bboxes[idxes]
def postprocess(self,bboxes, obj_probs, class_probs, image_shape=(416, 416), threshold=0.5):
bboxes = np.reshape(bboxes, [-1, 4])
# 将所有box还原成图片中真实的位置
bboxes[:, 0:1] *= float(image_shape[1])
bboxes[:, 1:2] *= float(image_shape[0])
bboxes[:, 2:3] *= float(image_shape[1])
bboxes[:, 3:4] *= float(image_shape[0])
bboxes = bboxes.astype(np.int32) # 转int
bbox_min_max = [0, 0, image_shape[1] - 1, image_shape[0] - 1]
# 防止识别框炸了
bboxes = self.bboxes_cut(bbox_min_max, bboxes)
# 平铺13*13*5
obj_probs = np.reshape(obj_probs, [-1])
# 平铺13*13*5,80
class_probs = np.reshape(class_probs, [len(obj_probs), -1])
# max类别概率对应的index
class_max_index = np.argmax(class_probs, axis=1)
class_probs = class_probs[np.arange(len(obj_probs)), class_max_index]
# 置信度*max类别概率=类别置信度scores
scores = obj_probs * class_probs
# 类别置信度scores>threshold的边界框bboxes留下
keep_index = scores > threshold
class_max_index = class_max_index[keep_index]
scores = scores[keep_index]
bboxes = bboxes[keep_index]
# 排序top_k(默认为400)
class_max_index, scores, bboxes = self.bboxes_sort(class_max_index, scores, bboxes)
# NMS
class_max_index, scores, bboxes = self.bboxes_nms(class_max_index, scores, bboxes)
return bboxes, scores, class_max_index
实现结果

以上就是python目标检测yolo2详解及预测代码复现的详细内容,更多关于yolo2预测复现的资料请关注Devmax其它相关文章!