背景介绍
我们日常工作中或多或少听说过以下的话:
Node是一个
非阻塞I/O(non-blocking I/O)和事件驱动(event-driven)的JavaScript运行环境(runtime),所以它非常适合用来构建I/O密集型应用,例如Web服务等。
不知道当你听到类似的话时会不会有和我一样的疑惑:单线程的Node为什么适合用来开发I/O密集型应用?按道理来说不是那些支持多线程的语言(例如Java和Golang)做这些工作更加有优势吗?
要搞明白上面的问题,我们需要知道Node的单线程指的是什么。
Node不是单线程的
其实我们说Node是单线程的,说的只是我们的JavaScript代码是在同一个线程(我们可以叫它主线程)里面运行的,而不是说Node只有一个线程在工作。实际上Node底层会使用libuv的多线程能力将一部分工作(基本都是I/O相关操作)放在一些主线程之外的线程里面执行,当这些任务完成后再以回调函数的方式将结果返回到主线程的JavaScript执行环境。
可以看看示意图:
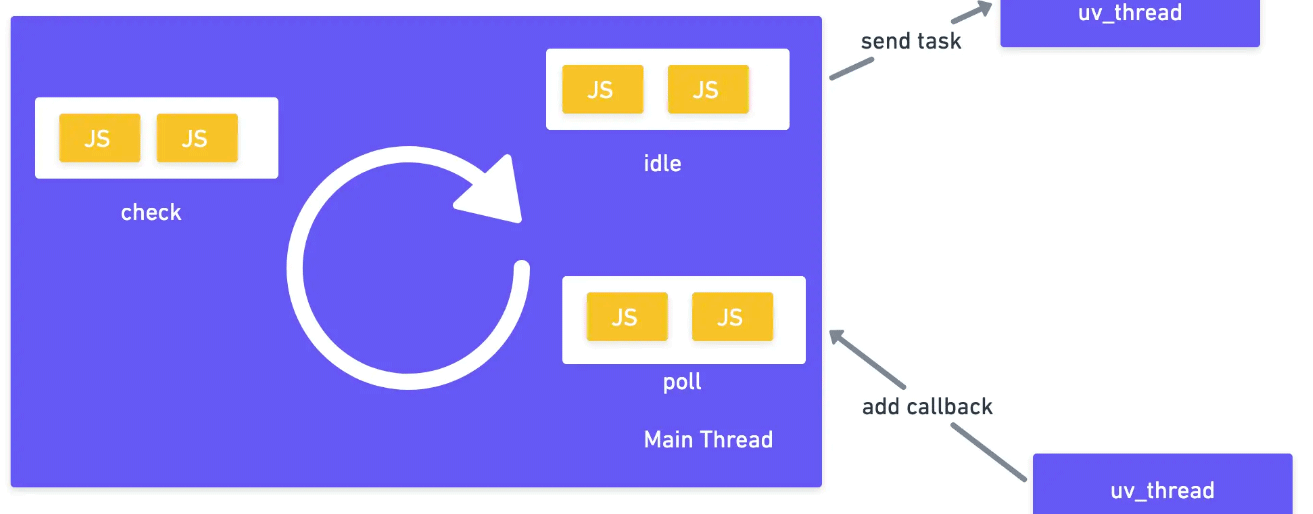
注: 上图是Node事件循环(Event Loop)的简化版,实际上完整的事件循环会有更多的阶段例如timers等。
Node适合做I/O密集型应用
从上面的分析中我们知道Node会将所有的I/O操作通过libuv的多线程能力分散到不同的线程里面执行,其余的操作都放在主线程里面执行。那么为什么这种做法就比Java或者Golang等其它语言更适合做I/O密集型应用呢?我们以开发Web服务为例,Java和Golang等主流后端编程语言的并发模型是基于线程(Thread-Based)的,这也就意味他们对于每一个网络请求都会创建一个单独的线程来处理。可是对于Web应用来说,主要还是对数据库的增删改查,或者请求其它外部服务等网络I/O操作,而这些操作最后都是交给操作系统的系统调用来处理的(无需应用线程参与),并且十分缓慢(相对于CPU时钟周期来说),因此被创建出来的线程大多数时间是无事可做的而且我们的服务还要承担额外的线程切换开销。和这些语言不一样的是Node没有为每个请求都创建一个线程,所有请求的处理都发生在主线程中,因此没有了线程切换的开销,并且它还会通过线程池的形式异步处理这些I/O操作,然后通过事件的形式告诉主线程结果从而避免阻塞主线程的执行,因此它理论上是更高效的。这里值得注意的是我只是说Node理论上是更快的,实际上真不一定。这是因为现实中一个服务的性能会受到很多方面的影响,我们这里只是考虑了并发模型这一个因素,而其它因素例如运行时消耗也会影响到服务的性能,举个例子,JavaScript是动态语言,数据的类型需要在运行时进行推断,而Golang和Java都是静态语言它们的数据类型在编译时就可以确定,所以它们实际执行起来可能会更快,占用内存也会更少。
Node不适合做CPU密集型任务
上面我们提到Node除了I/O相关的操作其余操作都会在主线程里面执行,所以当Node要处理一些CPU密集型的任务时,主线程会被阻塞住。我们来看一个CPU密集型任务的例子:
// node/cpu_intensive.js
const http = require('http')
const url = require('url')
const hardWork = () => {
// 100亿次毫无意义的计算
for (let i = 0; i < 10000000000; i ) {}
}
const server = http.createServer((req, resp) => {
const urlParsed = url.parse(req.url, true)
if (urlParsed.pathname === '/hard_work') {
hardWork()
resp.write('hard work')
resp.end()
} else if (urlParsed.pathname === '/easy_work') {
resp.write('easy work')
resp.end()
} else {
resp.end()
}
})
server.listen(8080, () => {
console.log('server is up...')
})在上面的代码中我们实现了拥有两个接口的HTTP服务:/hard_work接口是一个CPU密集型接口,因为它调用了hardWork这个CPU密集型函数,而/easy_work这个接口则很简单,直接返回一个字符串给客户端就可以了。为什么说hardWork函数是CPU密集型的呢?这是因为它都是在CPU的运算器里面对i进行算术运算而没有进行任何I/O操作。启动完我们的Node服务后,我们试着调用一下/hard_word接口:

我们可以看到/hard_work接口是会卡住的,这是因为它需要进行大量的CPU计算,所以需要比较久的时间才会执行完。而这个时候我们再看一下/easy_work这个接口有没有影响:

我们发现在/hard_work占用了CPU资源之后,无辜的/easy_work接口也被卡死了。原因就是hardWork函数阻塞了Node的主线程导致/easy_work的逻辑不会被执行。这里值得一提的是,只有Node这种基于事件循环的单线程执行环境才会有这种问题,Java和Golang等Thread-Based语言是不会存在这种问题的。那如果我们的服务真的需要运行CPU密集型任务怎么办?总不能换门语言吧?说好的All in JavaScript呢?别着急,对于处理CPU密集型任务,Node已经为我们准备好很多方案了,接下来就让我为大家介绍三种常用的方案,它们分别是: Cluster Module,Child Process和Worker Thread。
Cluster Module
概念介绍
Node很早(v0.8版本)就推出了Cluster模块。这个模块的作用就是通过一个父进程启动一群子进程来对网络请求进行负载均衡。因为文章的篇幅限制我们不会细聊Cluster模块有哪些API,感兴趣的读者后面可以看看官方文档,
这里我们直接看一下如何使用Cluster模块来优化上面CPU密集型的场景:
// node/cluster.js
const cluster = require('cluster')
const http = require('http')
const url = require('url')
// 获取CPU核数
const numCPUs = require('os').cpus().length
const hardWork = () => {
// 100亿次毫无意义的计算
for (let i = 0; i < 10000000000; i ) {}
}
// 判断当前是否是主进程
if (cluster.isMaster) {
// 根据当前机器的CPU核数创建同等数量的工作进程
for (var i = 0; i < numCPUs; i ) {
cluster.fork()
}
cluster.on('online', (worker) => {
console.log(`worker ${worker.process.pid} is online`)
})
cluster.on('exit', (worker, code, signal) => {
// 某个工作进程挂了之后,我们需要立马启动另外一个工作进程来替代
console.log(`worker ${worker.process.pid} exited with code $[code], and signal ${signal}, start a new one...`)
cluster.fork()
})
} else {
// 工作进程启动一个HTTP服务器
const server = http.createServer((req, resp) => {
const urlParsed = url.parse(req.url, true)
if (urlParsed.pathname === '/hard_work') {
hardWork()
resp.write('hard work')
resp.end()
} else if (urlParsed.pathname === '/easy_work') {
resp.write('easy work')
resp.end()
} else {
resp.end()
}
})
// 所有的工作进程都监听在同一个端口
server.listen(8080, () => {
console.log(`worker ${process.pid} server is up...`)
})
}在上面的代码中我们根据当前设备的CPU核数使用cluster.fork函数创建了同等数量的工作进程,而且这些工作进程都是监听在8080端口上面的。看到这里你或许会问所有的进程都监听在同一个端口会不会出现问题,这里其实是不会的,因为Cluster模块底层会做一些工作让最终监听在8080端口的是主进程,而主进程是所有流量的入口,它会接收HTTP连接并把它们打到不同的工作进程上面。话不多说,让我们运行一下这个node服务:
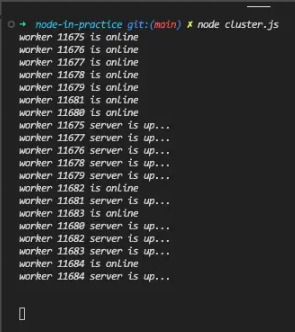
从上面的输出结果来看,cluster启动了10个worker(我的电脑是10核的)来处理web请求,这个时候我们再来请求一下/hard_work这个接口:

我们发现这个请求还是卡死的,接着我们再来看看Cluster模块有没有解决其它请求也被阻塞的问题:
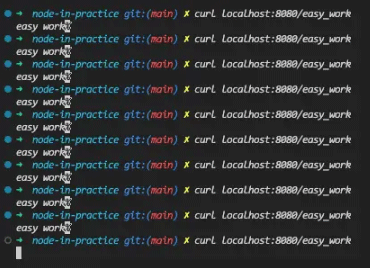
我们可以看到前面9个请求都是很顺利就返回结果的,可是到了第10个请求我们的接口就卡住了,这是为什么呢?原因就是我们一共开了10个工作进程,主进程在将流量打到子进程的时候采用的默认负载均衡策略是round-robin(轮流),因此第10个请求(其实是第11个,因为包括了第一个hard_work的请求)刚好回到第一个worker,而这个worker还没处理完hard_work的任务,因此这个easy_work的任务也就卡住了。cluster的负载均衡算法可以通过cluster.schedulingPolicy来修改,有兴趣的读者可以看一下官方文档。
从上面的结果来看Cluster Module似乎解决了一部分我们的问题,可是还是有一些请求受到了影响。那么Cluster Module在实际开发里面能不能被用来解决这个CPU密集型任务的问题呢?我的意见是:看情况。如果你的CPU密集型接口调用不频繁而且运算时间不会太长,你完全可以使用这种Cluster Module来优化。可是如果你的接口调用频繁并且每个接口都很耗时间的话,可能你需要看一下采用Child Process或者Worker Thread的方案了。
Cluster Module的优缺点
最后我们总结一下Cluster Module有什么优点:
-
资源利用率高:可以充分利用CPU的多核能力来提升请求处理效率。 -
API设计简单:可以让你实现简单的负载均衡和一定程度的高可用。这里值得注意的是我说的是一定程度的高可用,这是因为Cluster Module的高可用是单机版的,也就是当宿主机器挂了,你的服务也就挂了,因此更高的高可用肯定是使用分布式集群做的。 -
进程之间高度独立,避免某个进程发生系统错误导致整个服务不可用。
优点说完了,我们再来说一下Cluster Module不好的地方:
-
资源消耗大:每一个子进程都是独立的Node运行环境,也可以理解为一个独立的Node程序,因此占用的资源也是巨大的。 -
进程通信开销大:子进程之间的通信通过跨进程通信(IPC)来进行,如果数据共享频繁是一笔比较大的开销。 -
没能完全解决CPU密集任务:处理CPU密集型任务时还是有点抓紧见肘。
Child Process
在Cluster Module中我们可以通过启动更多的子进程来将一些CPU密集型的任务负载均衡到不同的进程里面,从而避免其余接口卡死。可是你也看到了,这个办法治标不治本,如果用户频繁调用CPU密集型的接口,那么还是会有一大部分请求会被卡死的。优化这个场景的另外一个方法就是child_process模块。
概念介绍
Child Process可以让我们启动子进程来完成一些CPU密集型任务。我们先来看一下主进程master_process.js的代码:
// node/master_process.js
const { fork } = require('child_process')
const http = require('http')
const url = require('url')
const server = http.createServer((req, resp) => {
const urlParsed = url.parse(req.url, true)
if (urlParsed.pathname === '/hard_work') {
// 对于hard_work请求我们启动一个子进程来处理
const child = fork('./child_process')
// 告诉子进程开始工作
child.send('START')
// 接收子进程返回的数据,并且返回给客户端
child.on('message', () => {
resp.write('hard work')
resp.end()
})
} else if (urlParsed.pathname === '/easy_work') {
// 简单工作都在主进程进行
resp.write('easy work')
resp.end()
} else {
resp.end()
}
})
server.listen(8080, () => {
console.log('server is up...')
})在上面的代码中对于/hard_work接口的请求,我们会通过fork函数开启一个新的子进程来处理,当子进程处理完毕我们拿到数据后就给客户端返回结果。这里值得注意的是当子进程完成任务后我没有释放子进程的资源,在实际项目里面我们也不应该频繁创建和销毁子进程因为这个消耗也是很大的,更好的做法是使用进程池。下面是子进程(child_process.js)的实现逻辑:
// node/child_process.js
const hardWork = () => {
// 100亿次毫无意义的计算
for (let i = 0; i < 10000000000; i ) {}
}
process.on('message', (message) => {
if (message === 'START') {
// 开始干活
hardWork()
// 干完活就通知子进程
process.send(message)
}
})子进程的代码也很简单,它在启动后会通过process.on的方式监听来自父进程的消息,在接收到开始命令后进行CPU密集型的计算,得出结果后返回给父进程。
运行上面master_process.js的代码,我们可以发现即使调用了/hard_work接口,我们还是可以任意调用/easy_work接口并且马上得到响应的,此处没有截图,过程大家脑补一下就可以了。
除了fork函数,child_process还提供了诸如exec和spawn等函数来启动子进程,并且这些进程可以执行任何的shell命令而不只是局限于Node脚本,有兴趣的读者后面可以通过官方文档了解一下,这里就不过多介绍了。
Child Process的优缺点
最后让我们来总结一下Child Process的优点有哪些:
-
灵活:不只局限于Node进程,我们可以在子进程里面执行任何的shell命令。这个其实是一个很大的优点,假如我们的CPU密集型操作是用其它语言实现的(例如c语言处理图像),而我们不想使用Node或者C Binding重新实现一遍的话我们就可以通过shell命令调用其它语言的程序,并且通过标准输入输出和它们进行通信从而得到结果。 -
细粒度的资源控制:不像Cluster Module,Child Process方案可以按照实际对CPU密集型计算的需求大小动态调整子进程的个数,做到资源的细粒度控制,因此它理论上是可以解决Cluster Module解决不了的CPU密集型接口调用频繁的问题。
不过Child Process的缺点也很明显:
-
资源消耗巨大:上面说它可以对资源进行细粒度控制的优点时,也说了它只是理论上可以解决CPU密集型接口频繁调用的问题,这是因为实际场景下我们的资源也是有限的,而每一个Child Process都是一个独立的操作系统进程,会消耗巨大的资源。因此对于频繁调用的接口我们需要采取能耗更低的方案也就是下面我会说的Worker Thread。 -
进程通信麻烦:如果启动的子进程也是Node应用的话还好办点,因为有内置的API来和父进程通信,如果子进程不是Node应用的话,我们只能通过标准输入输出或者其它方式来进行进程间通信,这是一件很麻烦的事。
Worker Thread
无论是Cluster Module还是Child Process其实都是基于子进程的,它们都有一个巨大的缺点就是资源消耗大。为了解决这个问题Node从v10.5.0版本(v12.11.0 stable)开始就支持了worker_threads模块,worker_thread是Node对于CPU密集型操作的轻量级的线程解决方案。
概念介绍
Node的Worker Thread和其它语言的thread是一样的,那就是并发地运行你的代码。这里要注意是并发而不是并行。并行只是意味着一段时间内多件事情同时发生,而并发是某个时间点多件事情同时发生。一个典型的并行例子就是React的Fiber架构,因为它是通过时分复用的方式来调度不同的任务来避免React渲染阻塞浏览器的其它行为的,所以本质上它所有的操作还是在同一个操作系统线程执行的。不过这里值得注意的是:虽然并发强调多个任务同时执行,在单核CPU的情况下,并发会退化为并行。这是因为CPU同一个时刻只能做一件事,当你有多个线程需要执行的话就需要通过资源抢占的方式来时分复用执行某些任务。不过这都是操作系统需要关心的东西,和我们没什么关系了。
上面说了Node的Worker Thead和其他语言线程的thread类似的地方,接着我们来看一下它们不一样的地方。如果你使用过其它语言的多线程编程方式,你会发现Node的多线程和它们很不一样,因为Node多线程数据共享起来实在是太麻烦了!Node是不允许你通过共享内存变量的方式来共享数据的,你只能用ArrayBuffer或者SharedArrayBuffer的方式来进行数据的传递和共享。虽然说这很不方便,不过这也让我们不需要过多考虑多线程环境下数据安全等一系列问题,可以说有好处也有坏处吧。
接着我们来看一下如何使用Worker Thread来处理上面的CPU密集型任务,
先看一下主线程(master_thread.js)的代码:
// node/master_thread.js
const { Worker } = require('worker_threads')
const http = require('http')
const url = require('url')
const server = http.createServer((req, resp) => {
const urlParsed = url.parse(req.url, true)
if (urlParsed.pathname === '/hard_work') {
// 对于每一个hard_work接口,我们都启动一个子线程来处理
const worker = new Worker('./child_process')
// 告诉子线程开始任务
worker.postMessage('START')
worker.on('message', () => {
// 在收到子线程回复后返回结果给客户端
resp.write('hard work')
resp.end()
})
} else if (urlParsed.pathname === '/easy_work') {
// 其它简单操作都在主线程执行
resp.write('easy work')
resp.end()
} else {
resp.end()
}
})
server.listen(8080, () => {
console.log('server is up...')
})在上面的代码中,我们的服务器每次接收到/hard_work请求都会通过new Worker的方式启动一个Worker线程来处理,在worker处理完任务之后我们再将结果返回给客户端,这个过程是异步的。接着再看一下子线程(worker_thead.js)的代码实现:
// node/worker_thread.js
const { parentPort } = require('worker_threads')
const hardWork = () => {
// 100亿次毫无意义的计算
for (let i = 0; i < 10000000000; i ) {}
}
parentPort.on('message', (message) => {
if (message === 'START') {
hardWork()
parentPort.postMessage()
}
})在上面的代码中,worker thread在接收到主线程的命令后开始执行CPU密集型操作,最后通过parentPort.postMessage的方式告知父线程任务已经完成,从API上看父子线程通信还是挺方便的。
Worker Thread的优缺点
最后我们还是总结一下Worker Thread的优缺点。
首先我觉得它的优点是:
-
资源消耗小:不同于Cluster Module和Child Process基于进程的方式,Worker Thread是基于更加轻量级的线程的,所以它的资源开销是相对较小的。不过麻雀虽小五脏俱全,每个Worker Thread都是有自己独立的v8引擎实例和事件循环系统的。这也就是说即使主线程卡死我们的Worker Thread也是可以继续工作的,基于这个其实我们可以做很多有趣的事情。 -
父子线程通信方便高效:和前面两种方式不一样,Worker Thread不需要通过IPC通信,所有数据都是在进程内部实现共享和传递的。
不过Worker Thread也不是完美的:
-
线程隔离性低:由于子线程不是在一个独立的环境执行的,所以某个子线程挂了还是会影响到其它线程,在这种情况下,你需要做一些额外的措施来保护其余线程不受影响。 -
线程数据共享实现麻烦:和其它后端语言比起来,Node的数据共享还是比较麻烦的,不过这其实也避免了它需要考虑很多多线程下数据安全的问题。
总结
在本篇文章中我为大家介绍了Node为什么适合做I/O密集型应用而很难处理CPU密集型任务的原因,并且为大家提供了三个可选方案来在实际开发中处理CPU密集型任务。每个方案其实都有利有弊,我们一定要根据实际情况进行选择,永远不要为了要用某个技术而一定要采取某个方案。
到此这篇关于Node处理CPU密集型任务有哪些方法的文章就介绍到这了,更多相关Node处理CPU密集内容请搜索Devmax以前的文章或继续浏览下面的相关文章希望大家以后多多支持Devmax!