
现在需要将course分组,然后选择出每一组里面的最大值和最小值,并保留下来
实现下面数据结果:

直接使用groupby函数,不能直接达到此效果,需要在groupby函数上添加apply和lambda函数
代码如下:
import pandas as pd
data = pd.read_excel('group_apply.xlsx')
data1 = data.groupby('course').apply(lambda t: t[(t['grade']==t['grade'].min()) ^ (t['grade']==t['grade'].max())])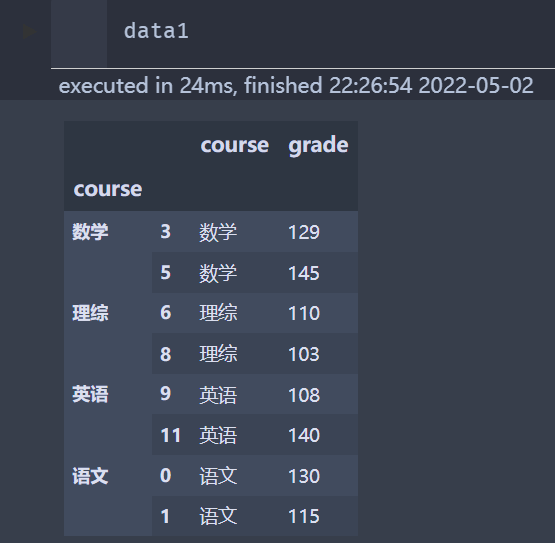
前面的index,是两列,所以需要处理一下,这个是groypby函数处理之后所产生,只需要删除即可
data2 = data1.reset_index(drop=True)

代码整合:
import pandas as pd
data = pd.read_excel('group_apply.xlsx')
data1 = data.groupby('course').apply(lambda t: t[(t['grade']==t['grade'].min()) ^ (t['grade']==t['grade'].max())])
data2 = data1.reset_index(drop=True)写入到excel中:

到此这篇关于python groupby函数实现分组后选取最值的文章就介绍到这了,更多相关python groupby 内容请搜索Devmax以前的文章或继续浏览下面的相关文章希望大家以后多多支持Devmax!