之前看过一篇脑洞大开的文章,介绍了各个大厂的前端反爬虫技巧,但也正如此文所说,没有100%的反爬虫方法,本文介绍一种简单的方法,来绕过所有这些前端反爬虫手段。
下面的代码以百度指数为例,代码已经封装成一个百度指数爬虫node库: https://github.com/Coffcer/baidu-index-spider
note: 请勿滥用爬虫给他人添麻烦
百度指数的反爬虫策略
观察百度指数的界面,指数数据是一个趋势图,当鼠标悬浮在某一天的时候,会触发两个请求,将结果显示在悬浮框里面:
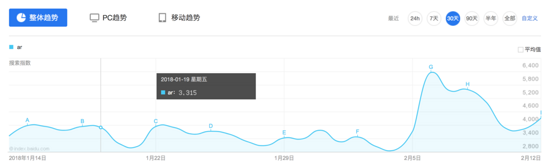
按照常规思路,我们先看下这个请求的内容:
请求 1:
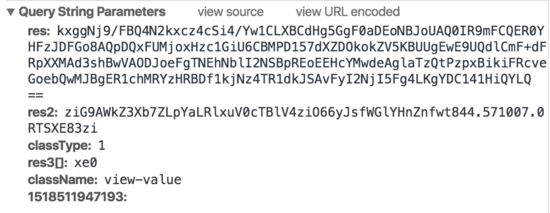
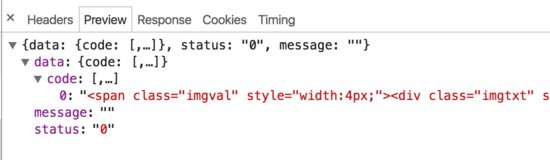
请求 2:

可以发现,百度指数实际上在前端做了一定的反爬虫策略。当鼠标移动到图表上时,会触发两个请求,一个请求返回一段html,一个请求返回一张生成的图片。html中并不包含实际数值,而是通过设置width和margin-left,来显示图片上的对应字符。并且请求参数上带有res、res1这种我们不知如何模拟的参数,所以用常规的模拟请求或者html爬取的方式,都很难爬到百度指数的数据。
爬虫思路
怎么突破百度这种反爬虫方法呢,其实也很简单,就是完全不去管他是如何反爬虫的。我们只需模拟用户操作,将需要的数值截图下来,做图像识别就行。步骤大概是:
- 模拟登录
- 打开指数页面
- 鼠标移动到指定日期
- 等待请求结束,截取数值部分的图片
- 图像识别得到值
- 循环第3~5步,就得到每一个日期对应的值
这种方法理论上能爬任何网站的内容,接下来我们来一步步实现爬虫,下面会用到的库:
- puppeteer 模拟浏览器操作
- node-tesseract tesseract的封装,用来做图像识别
- jimp 图片裁剪
安装Puppeteer, 模拟用户操作
Puppeteer是Google Chrome团队出品的Chrome自动化工具,用来控制Chrome执行命令。可以模拟用户操作,做自动化测试、爬虫等。用法非常简单,网上有不少入门教程,顺着本文看完也大概可以知道如何使用。
API文档: https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
安装:
npm install --save puppeteer
Puppeteer在安装时会自动下载Chromium,以确保可以正常运行。但是国内网络不一定能成功下载Chromium,如果下载失败,可以使用cnpm来安装,或者将下载地址改成淘宝的镜像,然后再安装:
npm config set PUPPETEER_DOWNLOAD_HOST=https://npm.taobao.org/mirrors npm install --save puppeteer
你也可以在安装时跳过Chromium下载,通过代码指定本机Chrome路径来运行:
// npm
npm install --save puppeteer --ignore-scripts
// node
puppeteer.launch({ executablePath: '/path/to/Chrome' });
实现
为版面整洁,下面只列出了主要部分,代码涉及到selector的部分都用了...代替,完整代码参看文章顶部的github仓库。
打开百度指数页面,模拟登录
这里做的就是模拟用户操作,一步步点击和输入。没有处理登录验证码的情况,处理验证码又是另一个话题了,如果你在本机登录过百度,一般不需要验证码。
// 启动浏览器,
// headless参数如果设置为true,Puppeteer将在后台操作你Chromium,换言之你将看不到浏览器的操作过程
// 设为false则相反,会在你电脑上打开浏览器,显示浏览器每一操作。
const browser = await puppeteer.launch({headless:false});
const page = await browser.newPage();
// 打开百度指数
await page.goto(BAIDU_INDEX_URL);
// 模拟登陆
await page.click('...');
await page.waitForSelecto('...');
// 输入百度账号密码然后登录
await page.type('...','username');
await page.type('...','password');
await page.click('...');
await page.waitForNavigation();
console.log(':white_check_mark: 登录成功');
模拟移动鼠标,获取需要的数据
需要将页面滚动到趋势图的区域,然后移动鼠标到某个日期上,等待请求结束,tooltip显示数值,再截图保存图片。
// 获取chart第一天的坐标
const position = await page.evaluate(() => {
const $image = document.querySelector('...');
const $area = document.querySelector('...');
const areaRect = $area.getBoundingClientRect();
const imageRect = $image.getBoundingClientRect();
// 滚动到图表可视化区域
window.scrollBy(0, areaRect.top);
return { x: imageRect.x, y: 200 };
});
// 移动鼠标,触发tooltip
await page.mouse.move(position.x, position.y);
await page.waitForSelector('...');
// 获取tooltip信息
const tooltipInfo = await page.evaluate(() => {
const $tooltip = document.querySelector('...');
const $title = $tooltip.querySelector('...');
const $value = $tooltip.querySelector('...');
const valueRect = $value.getBoundingClientRect();
const padding = 5;
return {
title: $title.textContent.split(' ')[0],
x: valueRect.x - padding,
y: valueRect.y,
width: valueRect.width padding * 2,
height: valueRect.height
}
});
截图
计算数值的坐标,截图并用jimp对裁剪图片。
await page.screenshot({ path: imgPath });
// 对图片进行裁剪,只保留数字部分
const img = await jimp.read(imgPath);
await img.crop(tooltipInfo.x, tooltipInfo.y, tooltipInfo.width, tooltipInfo.height);
// 将图片放大一些,识别准确率会有提升
await img.scale(5);
await img.write(imgPath);
图像识别
这里我们用Tesseract来做图像识别,Tesseracts是Google开源的一款OCR工具,用来识别图片中的文字,并且可以通过训练提高准确率。github上已经有一个简单的node封装: node-tesseract ,需要你先安装Tesseract并设置到环境变量。
Tesseract.process(imgPath, (err, val) => {
if (err || val == null) {
console.error(':x: 识别失败:' imgPath);
return;
}
console.log(val);
实际上未经训练的Tesseracts识别起来会有少数几个错误,比如把9开头的数字识别成`3,这里需要通过训练去提升Tesseracts的准确率,如果识别过程出现的问题都是一样的,也可以简单通过正则去修复这些问题。
封装
实现了以上几点后,只需组合起来就可以封装成一个百度指数爬虫node库。当然还有许多优化的方法,比如批量爬取,指定天数爬取等,只要在这个基础上实现都不难了。
const recognition = require('./src/recognition');
const Spider = require('./src/spider');
module.exports = {
async run (word, options, puppeteerOptions = { headless: true }) {
const spider = new Spider({
imgDir,
...options
}, puppeteerOptions);
// 抓取数据
await spider.run(word);
// 读取抓取到的截图,做图像识别
const wordDir = path.resolve(imgDir, word);
const imgNames = fs.readdirSync(wordDir);
const result = [];
imgNames = imgNames.filter(item => path.extname(item) === '.png');
for (let i = 0; i < imgNames.length; i ) {
const imgPath = path.resolve(wordDir, imgNames[i]);
const val = await recognition.run(imgPath);
result.push(val);
}
return result;
}
}
反爬虫
最后,如何抵挡这种爬虫呢,个人认为通过判断鼠标移动轨迹可能是一种方法。当然前端没有100%的反爬虫手段,我们能做的只是给爬虫增加一点难度。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Devmax。