一、re模块简介
Python 的 re 模块(Regular Expression 正则表达式)提供各种正则表达式的匹配操作,和 Perl 脚本的正则表达式功能类似,使用这一内嵌于 Python 的语言工具,尽管不能满足所有复杂的匹配情况,但足够在绝大多数情况下能够有效地实现对复杂字符串的分析并提取出相关信息。
二、正则表达式的基本概念
所谓的正则表达式,即就是说:
通过设定匹配的字符串的格式来在一个文本中找出所有符合该格式的一串字符。
1、正则表达式的语法介绍:
1)特殊字符:
, ., ^, $, {}, [], (), | 等
以上的特殊字符必须使用\来转义,这样才能使用原来的意思。
2)字符类
[] 中的一个或者是多个字符被称为字符类,字符类在匹配时如果没有指定量词则只会匹配其中的一个。
字符类的范围可以进行指定。
比如:
1> [a-zA-Z0-9]表示从a到z,从A到Z,0到9之间的任意一个字符;
2> 左方括号后面可以跟随一个 ^ ,表示否定一个字符类,字符类在匹配时如果没有指定量词则匹配其中一个;
3> 字符类的内部,除了 \ 之外,其他的特殊符号不在为原来的意思;
4> ^ 放在开头表示否定,放在其他位置表示自身。
3)速记法
. ------可以匹配换行符之外的任何一个字符
- \d ------匹配一个Unicode数字
- \D ------匹配一个Unicode非数字
- \s ------匹配Unicode空白
- \S ------匹配Unicode非空白
- \w ------匹配Unicode单词字符
- \W ------匹配Unicode非单字符
- ? ------匹配前面的字符0次或者1次
- *------匹配前面的字符0次或者多次
- (加号)------匹配前面的字符1次或者多次
- {m} ------匹配前面的表达式m次
- {m, } ------匹配前面的表达式至少m次
- {, n} ------匹配前面的表达式最多n次
- {m, n} ------匹配前面的表达式至少m次,最多n次
- () ------捕获括号内部的内容
2、Python中的正则表达式模块
Python中对于正则表达式的处理使用的是re模块,其中的语法可以参加上面所罗列出来的基本语法,尤其应该注意一下上述的 3)速记法 中的内容。因为在爬虫后需要数据分析时,往往会用到上面 3) 速记法 中所罗列出来的那些语法。
3、re模块的部分方法
1)re.compile()
我们首先在cmd中查看一下 re.compile() 方法的使用方法:
>>> import re
>>> help(re.compile)
Help on function compile in module re:
compile(pattern, flags=0)
Compile a regular expression pattern, returning a pattern object.
>>>
Compile a regular expression pattern, returning a pattern object.
的意思如下所示:
编译常规表达模式,返回模式对象。
使用re.compile(r, f)方法生成正则表达式对象,然后调用正则表达式对象的相应方法。这种做法的好处是生成正则对象之后可以多次使用。
2)re.findall()
同样的,我们先看help
>>> help(re.findall)
Help on function findall in module re:
findall(pattern, string, flags=0)
Return a list of all non-overlapping matches in the string.
If one or more capturing groups are present in the pattern, return
a list of groups; this will be a list of tuples if the pattern
has more than one group.
Empty matches are included in the result.注意这一段话:
Return a list of all non-overlapping matches in the string.
If one or more capturing groups are present in the pattern, return
a list of groups; this will be a list of tuples if the pattern
has more than one group.Empty matches are included in the result.
意思是说:
re.findall(s,start, end)
返回一个列表,如果正则表达式中没有分组,则列表中包含的是所有匹配的内容,
如果正则表达式中有分组,则列表中的每个元素是一个元组,元组中包含子分组中匹配到的内容,但是没有返回整个正则表达式匹配的内容。
3)re.finditer()
>>> help(re.finditer)
Help on function finditer in module re:
finditer(pattern, string, flags=0)
Return an iterator over all non-overlapping matches in the
string. For each match, the iterator returns a match object.
Empty matches are included in the result.
re.finditer(s, start, end)
返回一个可迭代对象
对可迭代对象进行迭代,每一次返回一个匹配对象,可以调用匹配对象的group()方法查看指定组匹配到的内容,0表示整个正则表达式匹配到的内容
4) re.search()
>>> help(re.search)
Help on function search in module re:
search(pattern, string, flags=0)
Scan through string looking for a match to the pattern, returning
a match object, or None if no match was found.
re.search(s, start, end)
返回一个匹配对象,倘若没匹配到,就返回None
search方法只匹配一次就停止,不会继续往后匹配
5)re.match()
>>> help(re.match)
Help on function match in module re:
match(pattern, string, flags=0)
Try to apply the pattern at the start of the string, returning
a match object, or None if no match was found.re.match(s, start, end)
如果正则表达式在字符串的起始处匹配,就返回一个匹配对象,否则返回None
6) re.sub()
>>> help(re.sub)
Help on function sub in module re:
sub(pattern, repl, string, count=0, flags=0)
Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the match object and must return
a replacement string to be used.re.sub(x, s, m)
返回一个字符串。每一个匹配的地方用x进行替换,返回替换后的字符串,如果指定m,则最多替换m次。对于x可以使用/i或者/gid可以是组名或者编号来引用捕获到的内容。
模块方法re.sub(r, x, s, m)中的x可以使用一个函数。此时我们就可以对捕获到的内容推过这个函数进行处理后再替换匹配到的文本。
7) re.subn()
>>> help(re.subn)
Help on function subn in module re:
subn(pattern, repl, string, count=0, flags=0)
Return a 2-tuple containing (new_string, number).
new_string is the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in the source
string by the replacement repl. number is the number of
substitutions that were made. repl can be either a string or a
callable; if a string, backslash escapes in it are processed.
If it is a callable, it's passed the match object and must
return a replacement string to be used.rx.subn(x, s, m)
与re.sub()方法相同,区别在于返回的是二元组,其中一项是结果字符串,一项是做替换的个数
8) re.split()
>>> help(re.split)
Help on function split in module re:
split(pattern, string, maxsplit=0, flags=0)
Split the source string by the occurrences of the pattern,
returning a list containing the resulting substrings. If
capturing parentheses are used in pattern, then the text of all
groups in the pattern are also returned as part of the resulting
list. If maxsplit is nonzero, at most maxsplit splits occur,
and the remainder of the string is returned as the final element
of the list.re.split(s, m)
分割字符串,返回一个列表,用正则表达式匹配到的内容对字符串进行分割
如果正则表达式中存在分组,则把分组匹配到的内容放在列表中每两个分割的中间作为列表的一部分
三、正则表达式使用的实例
我们就爬一个虫来进行正则表达式的使用吧:
爬取豆瓣电影的Top250榜单并且获取到每一部电影的相应评分。
import re
import requests
if __name__ == '__main__':
"""
测试函数(main)
"""
N = 25
j = 1
for i in range(0, 226, 25):
url = f'https://movie.douban.com/top250?start={i}&filter='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36 Edg/89.0.774.63'
}
response = requests.get(url=url, headers=headers)
result = re.findall(r'<a href="(\S )">\s '
r'<img width="100" alt="(\S )" src="\S " class="">\s '
r'</a>', response.text)
for movie in result:
url_0 = movie[0]
response_0 = requests.get(url=url_0, headers=headers)
score = re.findall(r'<strong class="ll rating_num" property="v:average">(\S )'
r'</strong>\s '
r'<span property="v:best" content="10.0"></span>',
response_0.text)[0]
print(j, end=' ')
j = 1
print(movie[1], end=' ')
print(movie[0], end=' ')
print(f'评分 : {score}')
i = N
在这里,我们的正则表达式用来提取了电影名称、电影的url链接,然后再通过访问电影的url链接进入电影的主页并获取到电影的评分信息。
主要的正则表达式使用代码为:
1、获取电影名称以及电影url:
result = re.findall(r'<a href="(\S )">\s '
r'<img width="100" alt="(\S )" src="\S " class="">\s '
r'</a>', response.text)
2、获取电影的相应评分:
score = re.findall(r'<strong class="ll rating_num" property="v:average">(\S )'
r'</strong>\s '
r'<span property="v:best" content="10.0"></span>',
response_0.text)[0]
最后我们需要再说一下,这里爬虫的美中不足的地方就是这个接口似乎不能够爬取到250了,只能爬取到248个电影,这个应该只是接口的问题,但是影响不是很大啦。
如下图所示:
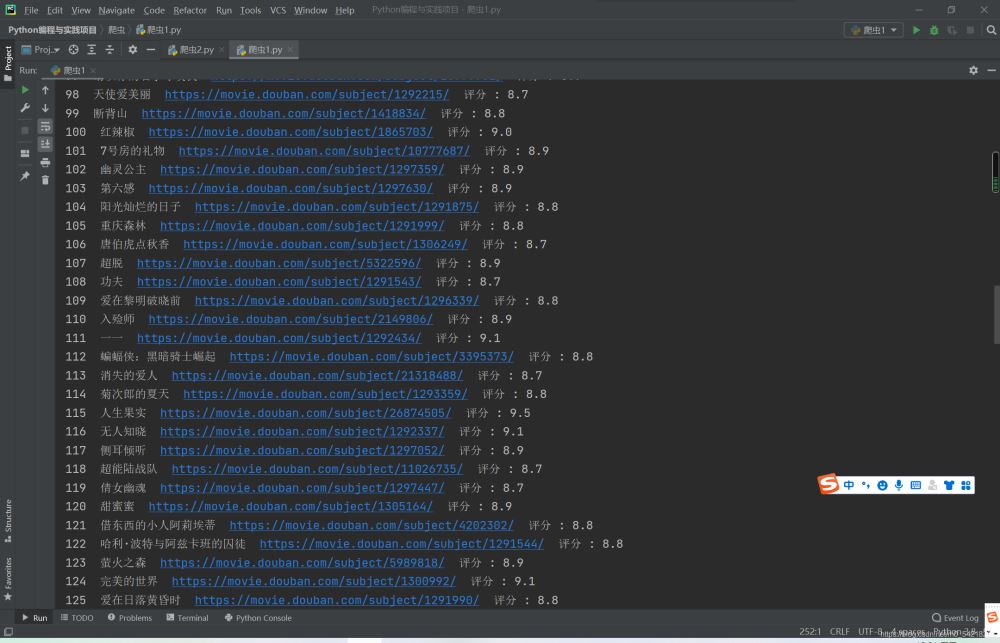
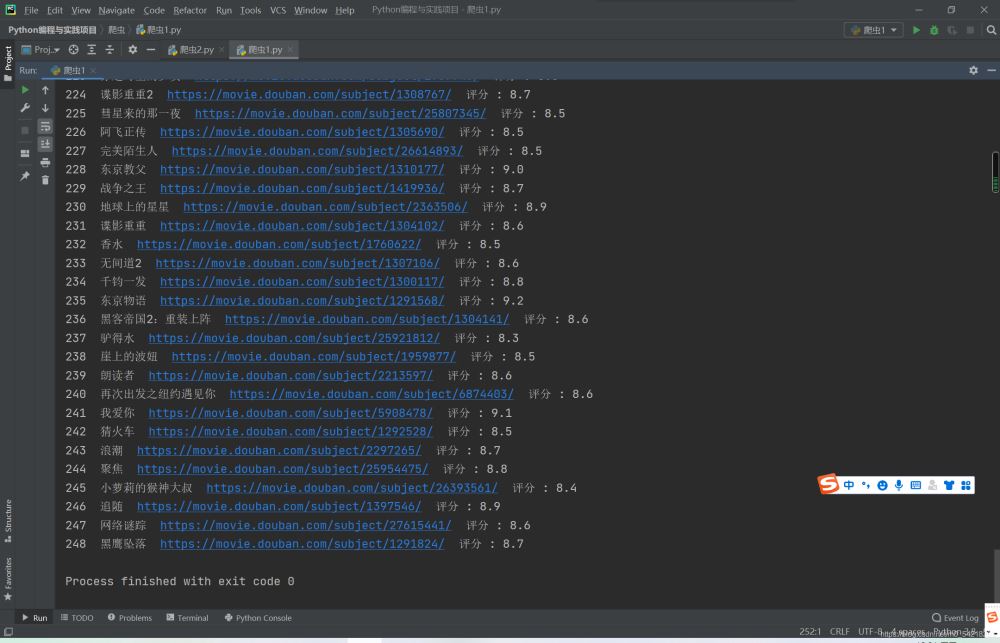
正则表达式的简介我也就写到这里就结束了啦,希望对大家有所帮助啦。
当然我为了写这篇博文中的豆瓣爬虫,已经被豆瓣封了;
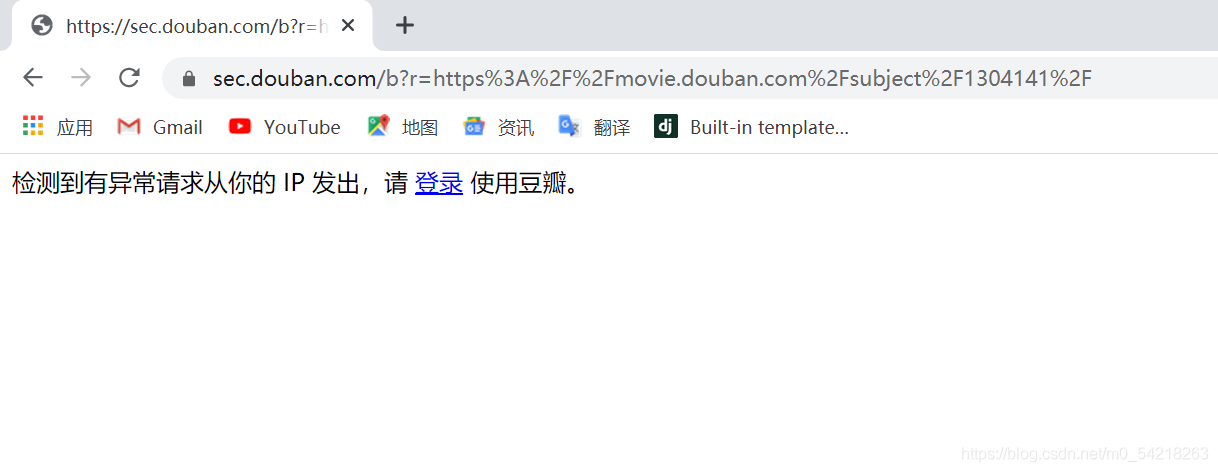
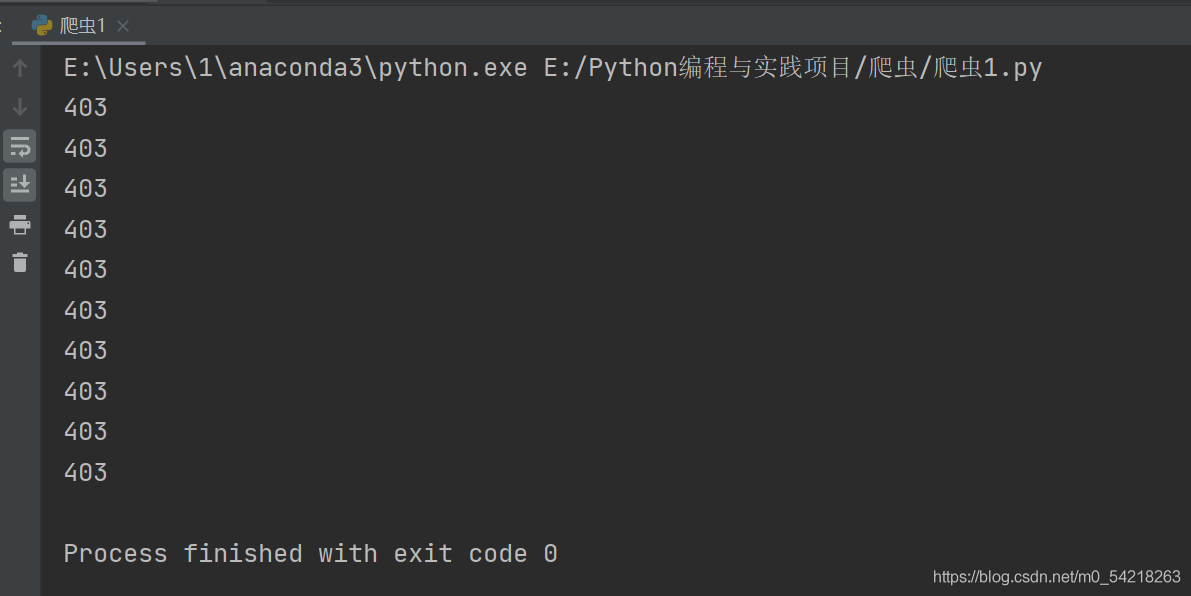
至于 403 错误是因为:访问的端口被禁止,或者原来的端口被修改所致。
这里显然是我被禁止了。
总结
到此这篇关于Python正则表达式re模块讲解以及其案例举例的文章就介绍到这了,更多相关Python re模块案例内容请搜索Devmax以前的文章或继续浏览下面的相关文章希望大家以后多多支持Devmax!